
EC2 インスタンスの Auto Recovery(インスタンスの自動復旧)発動時に EventBridge と SSM Run Command を使って特定のコマンドを実行する
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
Auto Recovery(インスタンスの自動復旧)発動時に特定のアクションを行いたいケースがありましたので、EventBridge と Systems Manager(以降 SSM)Run Command を使って検証してみました。
Auto Recovery(インスタンスの自動復旧)とは
Auto Recovery(インスタンスの自動復旧)は、物理ホストの電源やネットワーク接続喪失など、AWS の基盤の問題で EC2 インスタンスがダウンしたときに自動でインスタンスの復旧をしてくれる機能です。
Auto Recovery(インスタンスの自動復旧)が発動する際は StatusCheckFailed_System というメトリクスが検知されます。
検証
構成イメージはこちらです。
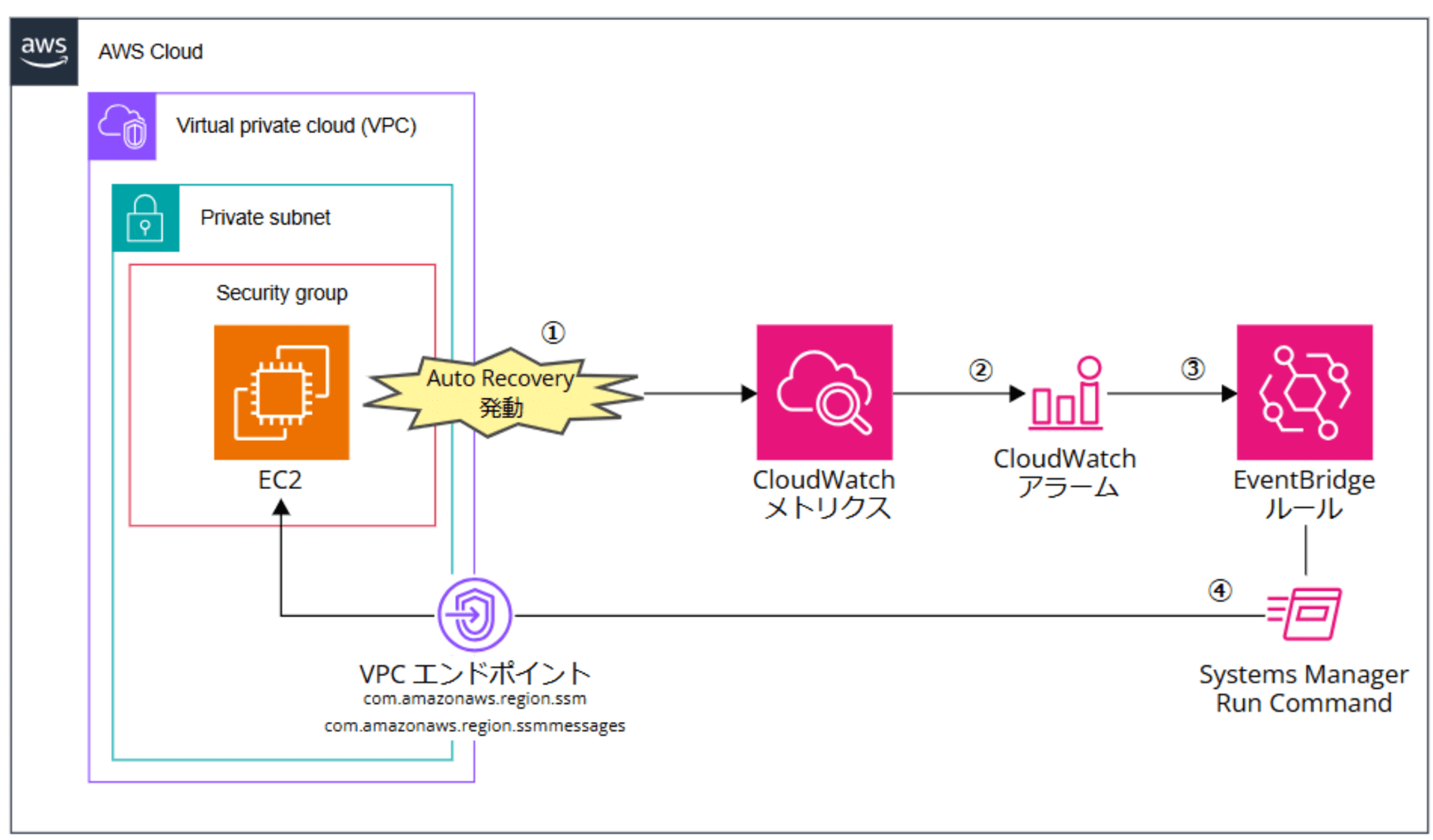
0. 留意事項
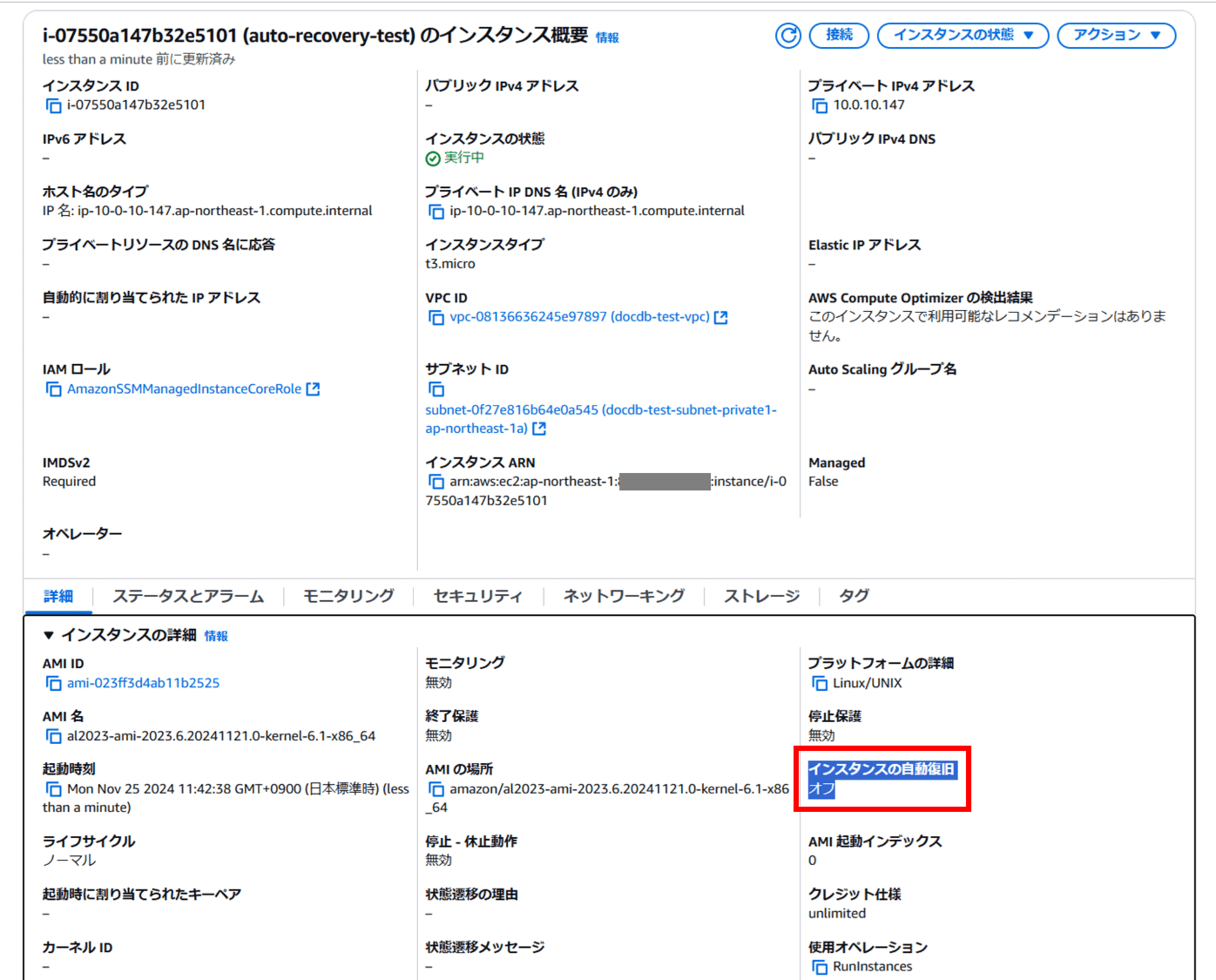
1. 新しく EC2 を起動する場合はデフォルトで Auto Recovery(インスタンスの自動復旧)がオンになっているため、一旦これをオフにする
クイックスタートで提供されている以下の AMI からプライベートサブネットに検証用 EC2 インスタンスを起動しました。
- Amazon Linux 2023 AMI 2023.6.20241121.0 x86_64 HVM kernel-6.1
- AMI ID:ami-023ff3d4ab11b2525
[アップデート] デフォルトでEC2インスタンスがAuto Recoveryするようになりました | DevelopersIO にあるように、新しく EC2 を起動する場合はデフォルトで Auto Recovery(インスタンスの自動復旧)がオンになっています。[アクション] - [インスタンスの設定] - [自動復旧動作を変更] より、自動復旧を一旦オフにします。この後 CloudWatch Alarm 側でオンにします。
2. SSM エージェントの自動起動設定を確認
SSM Run Command は SSM の機能なので、SSM エージェントが起動していて、かつ SSM フリートマネージャーから EC2 インスタンスがマネージドインスタンスとして確認できている必要があります。以下のブログを参考に SSM 接続用の VPC エンドポイントを追加しました。
セッションマネージャーで接続し、SSM エージェントのバージョンと起動状態を確認します。
SSM エージェントのバージョン確認コマンド
yum info amazon-ssm-agent
実行結果
sh-5.2$ yum info amazon-ssm-agent
Amazon Linux 2023 repository 48 MB/s | 29 MB 00:00
Amazon Linux 2023 Kernel Livepatch repository 46 kB/s | 11 kB 00:00
Installed Packages
History database cannot be created, using in-memory database instead: SQLite error on "/var/lib/dnf/history.sqlite": Open failed: unable to open database file
Name : amazon-ssm-agent
Version : 3.3.987.0
Release : 1.amzn2023
Architecture : x86_64
Size : 125 M
Source : amazon-ssm-agent-3.3.987.0-1.amzn2023.src.rpm
Repository : @System
Summary : Manage EC2 Instances using SSM APIs
URL : http://docs.aws.amazon.com/ssm/latest/APIReference/Welcome.html
License : ASL 2.0
Description : This package provides Amazon SSM Agent for managing EC2 Instances using SSM APIs
sh-5.2$
バージョンは 3.3.987.0 でした。
今回はクイックスタートで提供されている AMI を使用したため SSM エージェントがプリインストールされていました。必要に応じてインストールしてください。
SSM エージェントの状態確認
sudo systemctl status amazon-ssm-agent
実行結果
sh-5.2$ sudo systemctl status amazon-ssm-agent
● amazon-ssm-agent.service - amazon-ssm-agent
Loaded: loaded (/usr/lib/systemd/system/amazon-ssm-agent.service; enabled; preset: enabled)
Active: active (running) since Mon 2024-11-25 05:06:09 UTC; 2min 14s ago
Main PID: 1583 (amazon-ssm-agen)
Tasks: 29 (limit: 1058)
Memory: 93.3M
CPU: 559ms
CGroup: /system.slice/amazon-ssm-agent.service
├─1583 /usr/bin/amazon-ssm-agent
├─1630 /usr/bin/ssm-agent-worker
├─1729 /usr/bin/ssm-session-worker cm-kitani.emi-xkkgk9fj73qu7qb9nlfty67z28
└─1750 sh
Nov 25 05:06:10 ip-10-0-10-147.ap-northeast-1.compute.internal amazon-ssm-agent[1583]: 2024-11-25 05:06:10.0480 INFO [CredentialRefresher] Starting credentials refresher loop
Nov 25 05:06:10 ip-10-0-10-147.ap-northeast-1.compute.internal amazon-ssm-agent[1583]: 2024-11-25 05:06:10.0901 INFO EC2RoleProvider Successfully connected with instance profile role credentials
Nov 25 05:06:10 ip-10-0-10-147.ap-northeast-1.compute.internal amazon-ssm-agent[1583]: 2024-11-25 05:06:10.0904 INFO [CredentialRefresher] Credentials ready
Nov 25 05:06:10 ip-10-0-10-147.ap-northeast-1.compute.internal amazon-ssm-agent[1583]: 2024-11-25 05:06:10.0906 INFO [CredentialRefresher] Next credential rotation will be in 29.999992157316665 minutes
Nov 25 05:06:11 ip-10-0-10-147.ap-northeast-1.compute.internal amazon-ssm-agent[1583]: 2024-11-25 05:06:11.1218 INFO [amazon-ssm-agent] [LongRunningWorkerContainer] [WorkerProvider] Worker ssm-agent-worker is not running,>
Nov 25 05:06:11 ip-10-0-10-147.ap-northeast-1.compute.internal amazon-ssm-agent[1583]: 2024-11-25 05:06:11.1314 INFO [amazon-ssm-agent] [LongRunningWorkerContainer] [WorkerProvider] Worker ssm-agent-worker (pid:1630) star>
Nov 25 05:06:11 ip-10-0-10-147.ap-northeast-1.compute.internal amazon-ssm-agent[1583]: 2024-11-25 05:06:11.1314 INFO [amazon-ssm-agent] [LongRunningWorkerContainer] Monitor long running worker health every 60 seconds
Nov 25 05:08:12 ip-10-0-10-147.ap-northeast-1.compute.internal useradd[1740]: new group: name=ssm-user, GID=1001
Nov 25 05:08:12 ip-10-0-10-147.ap-northeast-1.compute.internal useradd[1740]: new user: name=ssm-user, UID=1001, GID=1001, home=/home/ssm-user, shell=/bin/bash, from=none
Nov 25 05:08:23 ip-10-0-10-147.ap-northeast-1.compute.internal sudo[1752]: ssm-user : TTY=pts/0 ; PWD=/usr/bin ; USER=root ; COMMAND=/usr/bin/systemctl status amazon-ssm-agent
sh-5.2$
状態は active (running) でした。
さて、Auto Recovery(インスタンスの自動復旧)が発動した際も SSM エージェントは自動で起動してほしいので、SSM エージェントは自動起動するようにしておきます。
自動起動設定が有効になっているか確認
sudo systemctl is-enabled amazon-ssm-agent
実行結果
sh-5.2$ sudo systemctl is-enabled amazon-ssm-agent
enabled
sh-5.2$
enabled と表示され、自動起動設定が有効であることが確認できました。有効になっていなかったら sudo systemctl enable amazon-ssm-agent コマンドで自動起動するようにしておきます。
3. CloudWatch Alarm を作成
EC2 インスタンスのアクションから CloudWatch アラームを作成します。
- [モニタリングとトラブルシューティング] - [CloudWatch アラームの管理]
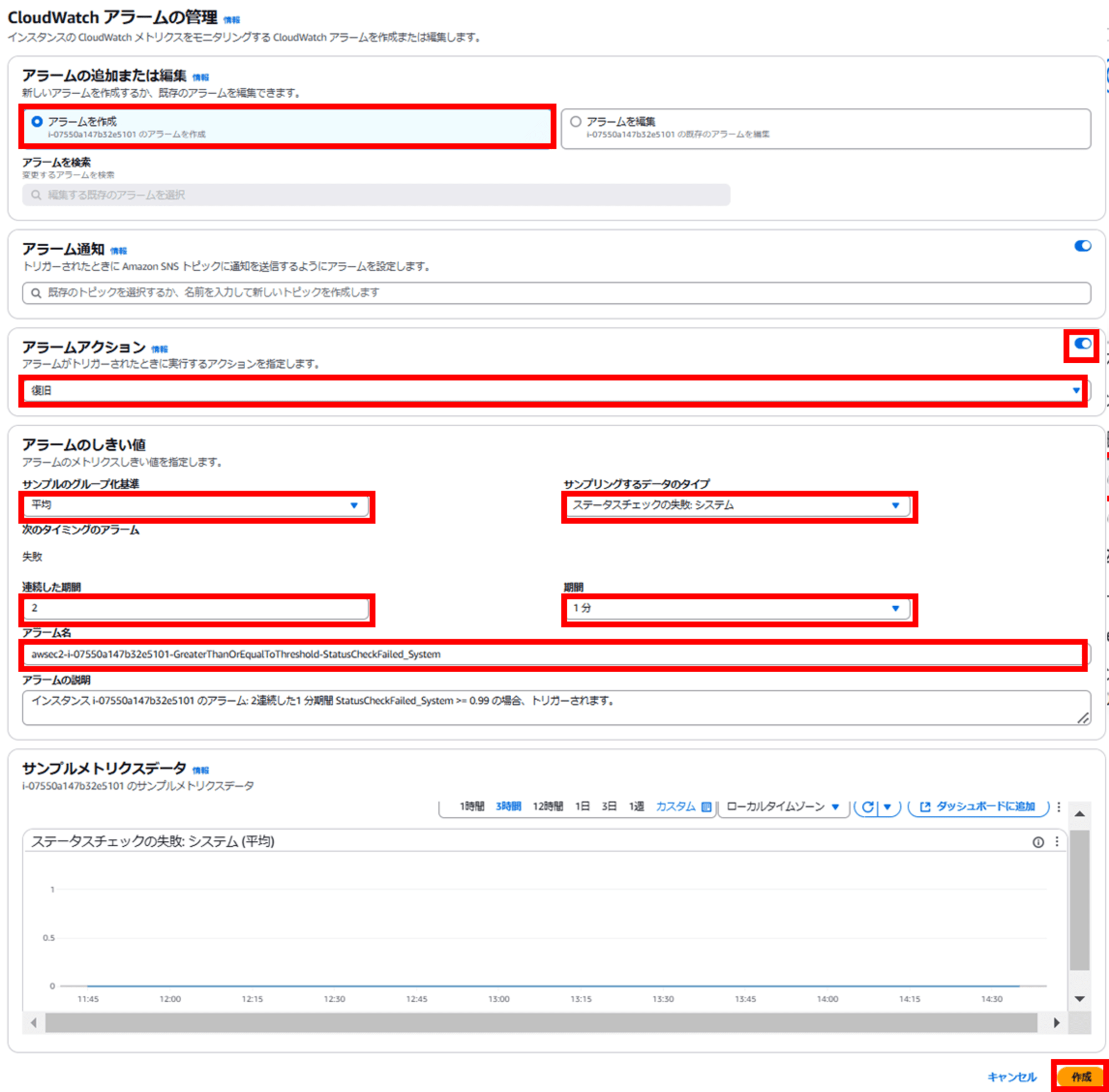
- アラームアクション:復旧
- サンプルのグループ化基準:平均
- サンプリングするデータのタイプ:ステータスチェックの失敗_システム(StatusCheckFailed_System)
- 連続した期間:2(例)
- 期間:1 分(例)
評価期間についてはドキュメントに以下の記載がありましたので、参考にしています。
復旧アラームを各 1 分間の 2 回の評価期間に設定することをお勧めします。
Amazon CloudWatch アラームへの復旧アクションの追加
余談:StatusCheckFailed_System がメトリクスとして表示されるまでラグがある
CloudWatch の「すべてのメトリクス」から StatusCheckFailed_System を確認したところ、EC2 作成してからすぐは表示されず、少し時間がたってから表示されるようになりました。
▼ EC2 インスタンス起動直後
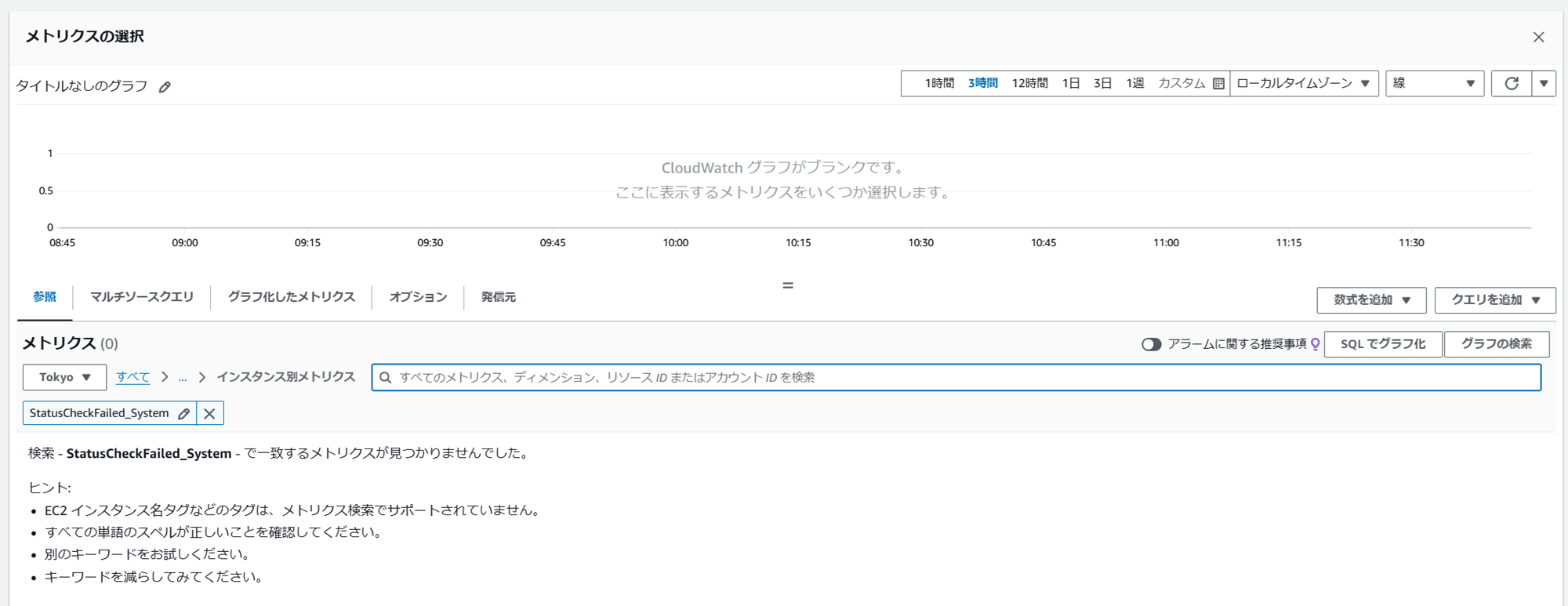
▼ EC2 インスタンスを起動してお昼ご飯を食べて戻ってきた後
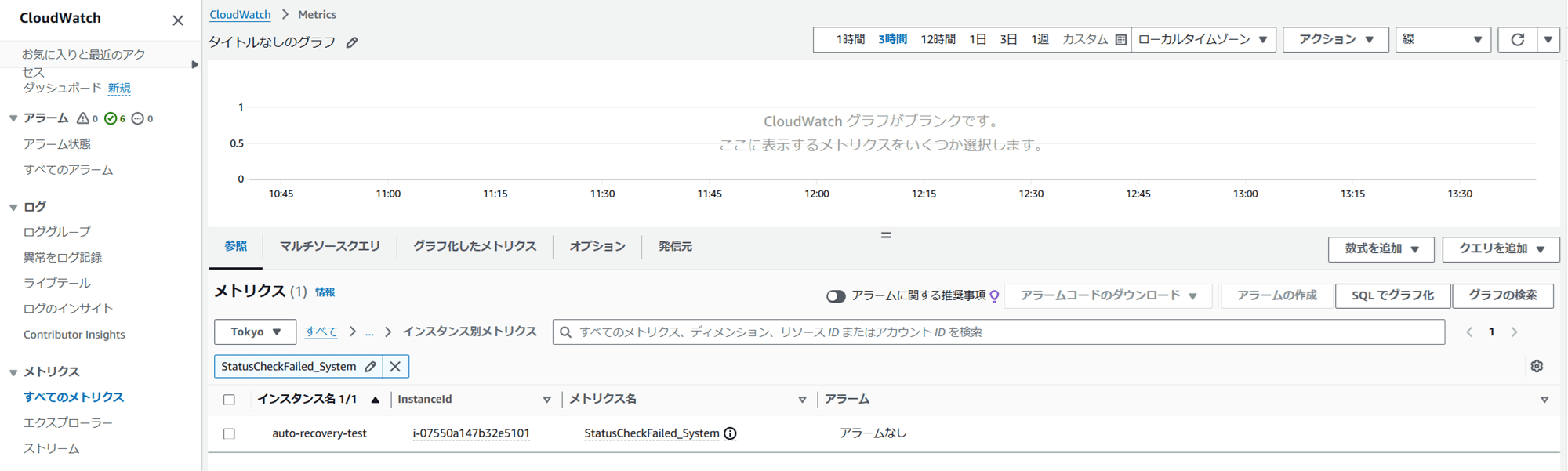
4. EventBridge ルールで SSM Run Command をトリガー
EventBridge ルールを作成します。
EventBridge コンソールの「ルール」から「ルールを作成」をクリックします。
- イベントバス:default
- ルールタイプ:イベントパターンを持つルール
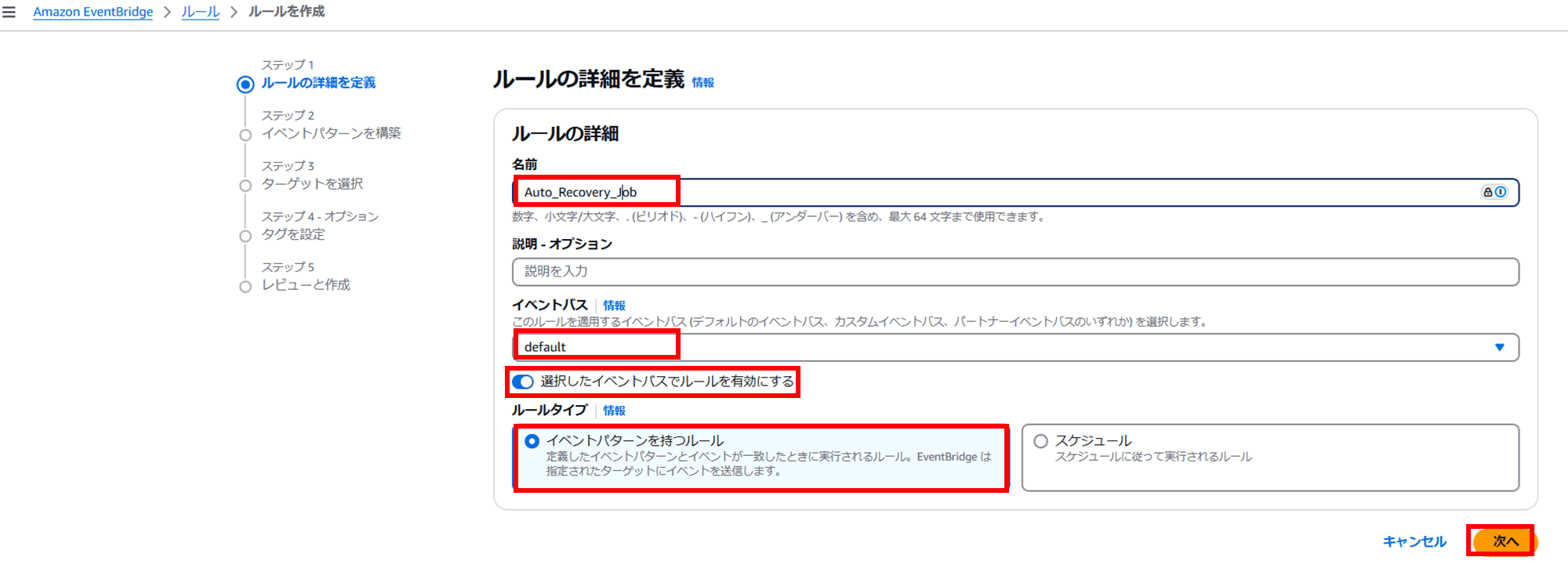
- イベントソース:その他
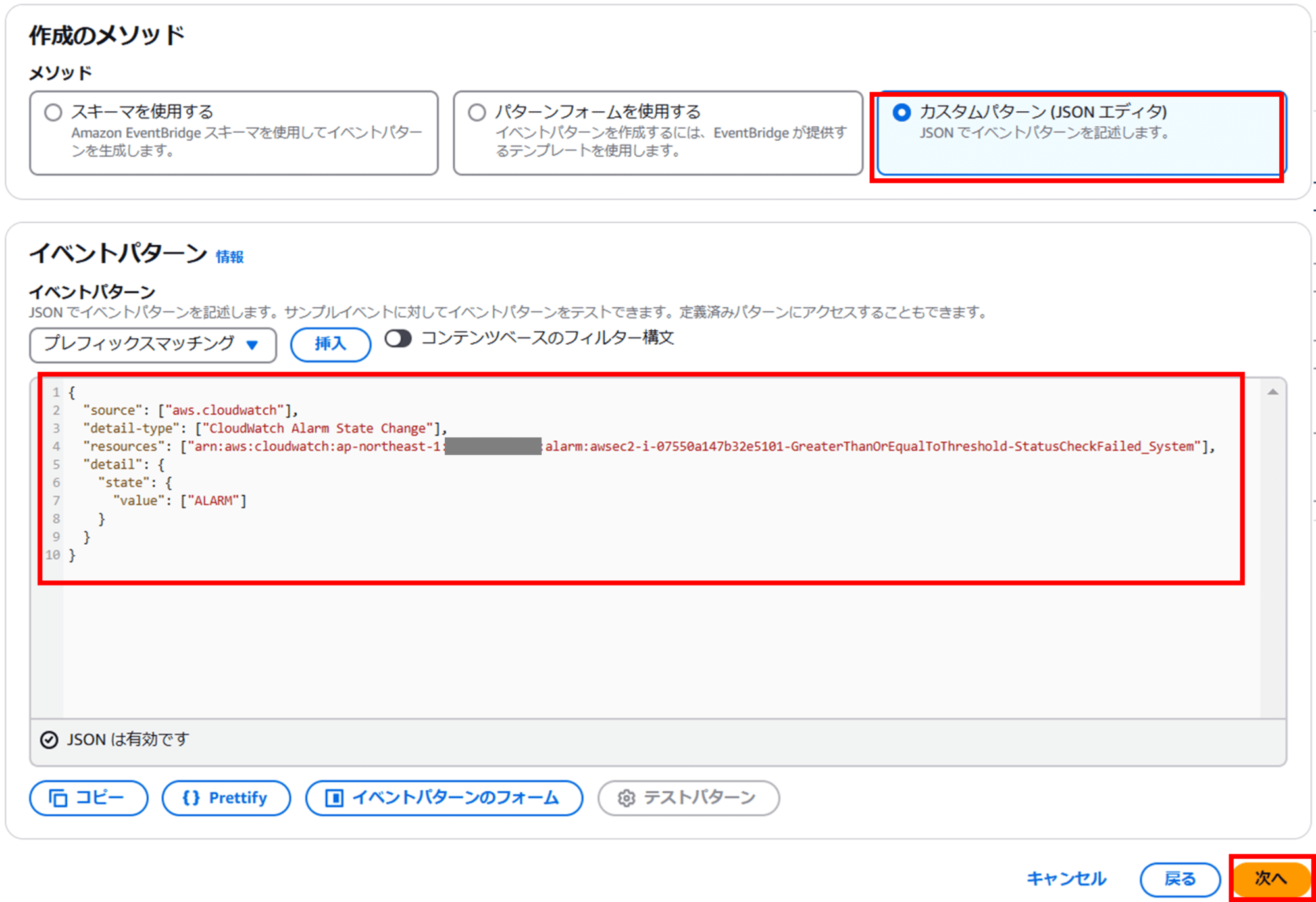
- イベントパターン
- 以下は状態が「ALARM」になった際にアクションを実行するイベントパターンです。
{
"source": ["aws.cloudwatch"],
"detail-type": ["CloudWatch Alarm State Change"],
"resources": ["<作成した CloudWatch Alarm の ARN>"],
"detail": {
"state": {
"value": ["ALARM"]
}
}
}
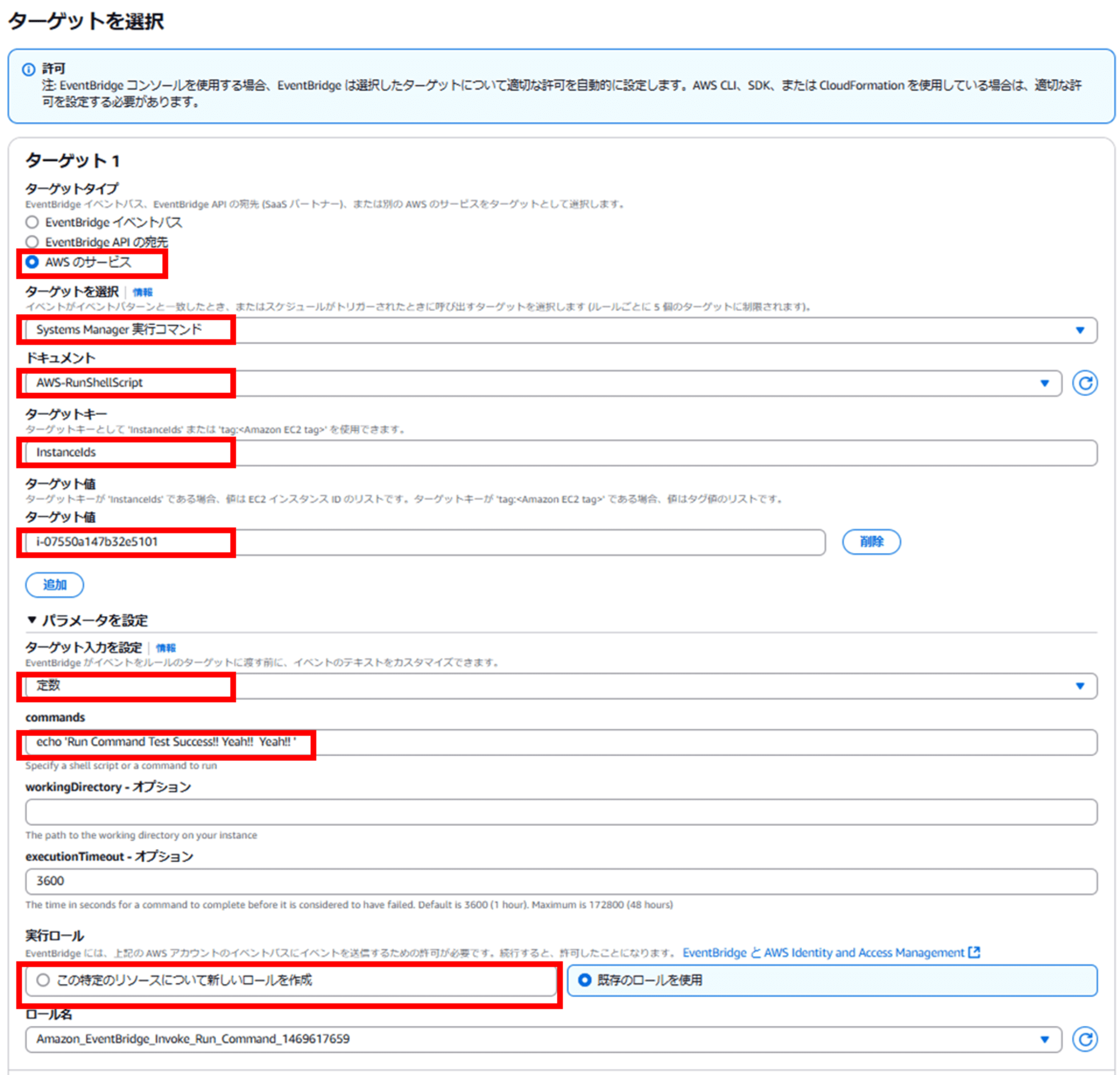
- ターゲットタイプ:AWS のサービス
- ターゲットを選択:Systems Manager 実行コマンド
- ドキュメント:AWS-RunShellScript
- ターゲットキー:InstanceIds
- ターゲット値:<EC2 インスタンス ID>
- ターゲット入力を設定:定数
- commands:<実行したいコマンド>
- 今回は
echo 'Run Command Test Success!! Yeah!! Yeah!! 'としています。
- 今回は
- 実行ロール:この特定のリソースについて新しいロールを作成
余談:イベントパターンを間違ってアクションがコマンドが二回実行されてしまう
最初に CloudWatch アラームの詳細画面下部のイベントパターンをそのまま使って EventBridge ルールを作成したところ、「ステータスが変更されたらアクションが実行される」、つまり、OK ⇒ ALARM で実行、ALARM ⇒ OK で実行、と、二回実行されてしまうルールになってしまいました。
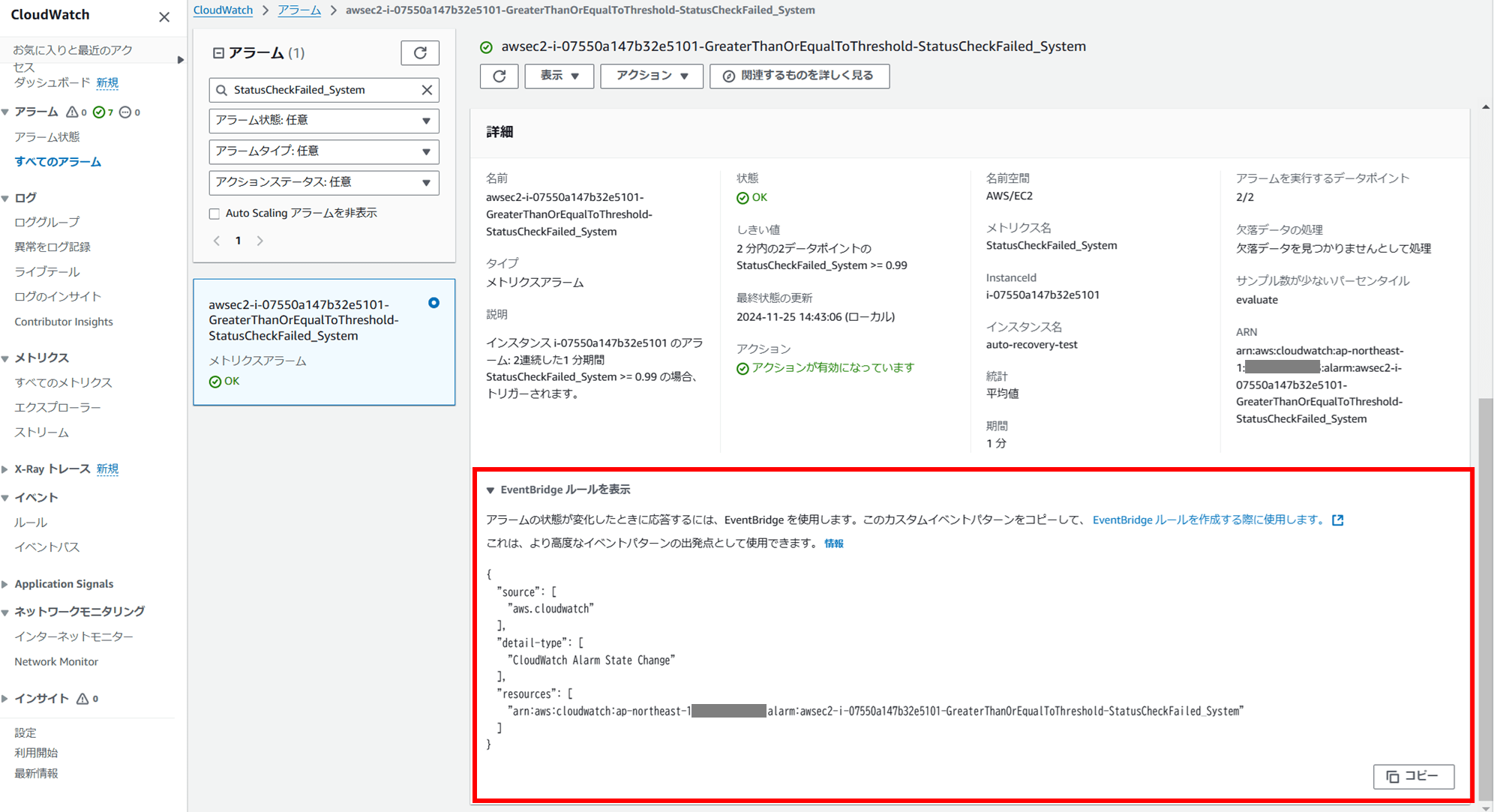
OK ⇒ ALARM の時のみイベントをトリガーするには、"detail" ブロックで指定しましょう。
その他の設定はデフォルトのままにします。
「確認と更新」画面で、ターゲットへの入力を確認します。「表示」をクリックすると、
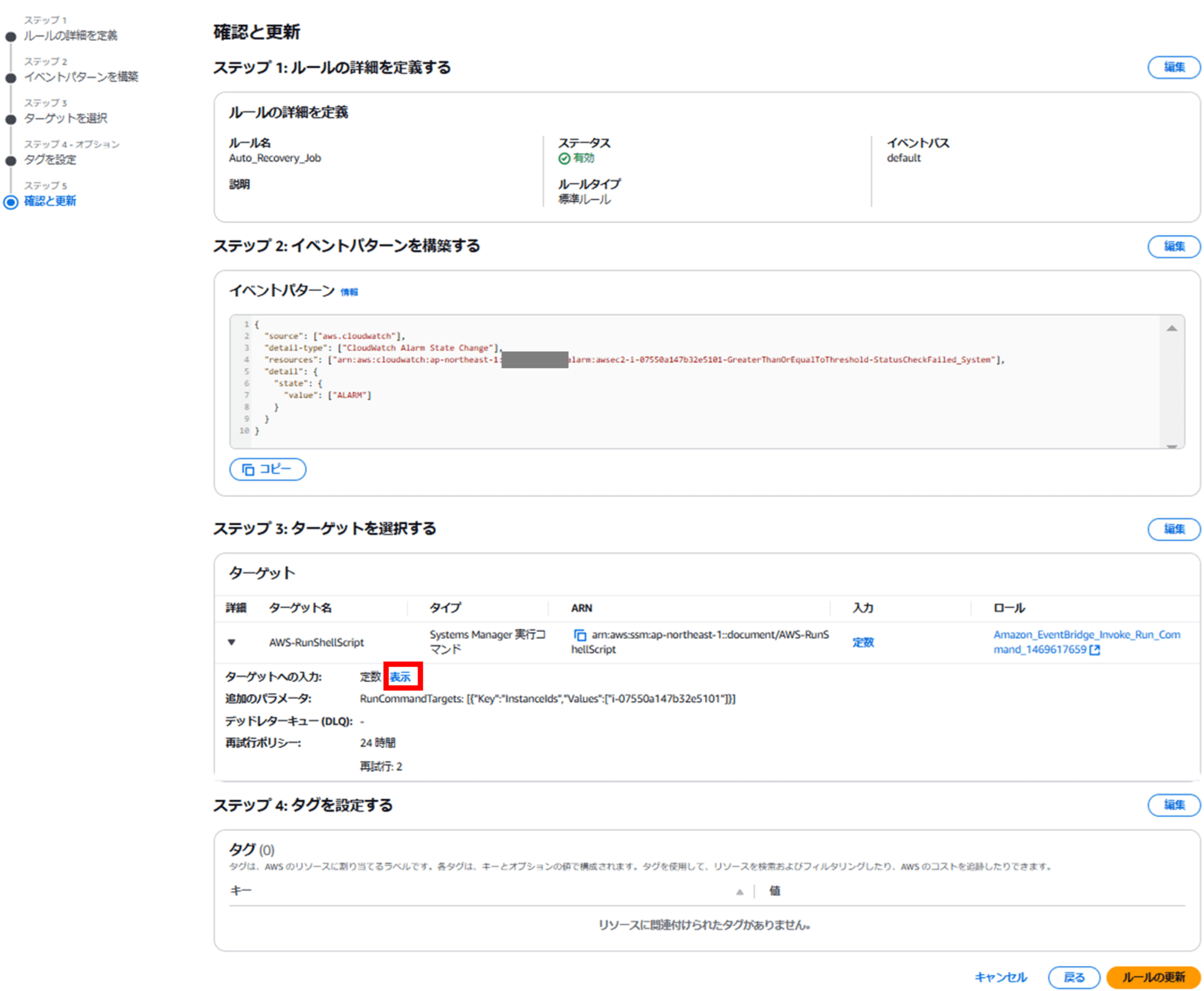
このように SSM Run Command で実行したいコマンドが表示されます。
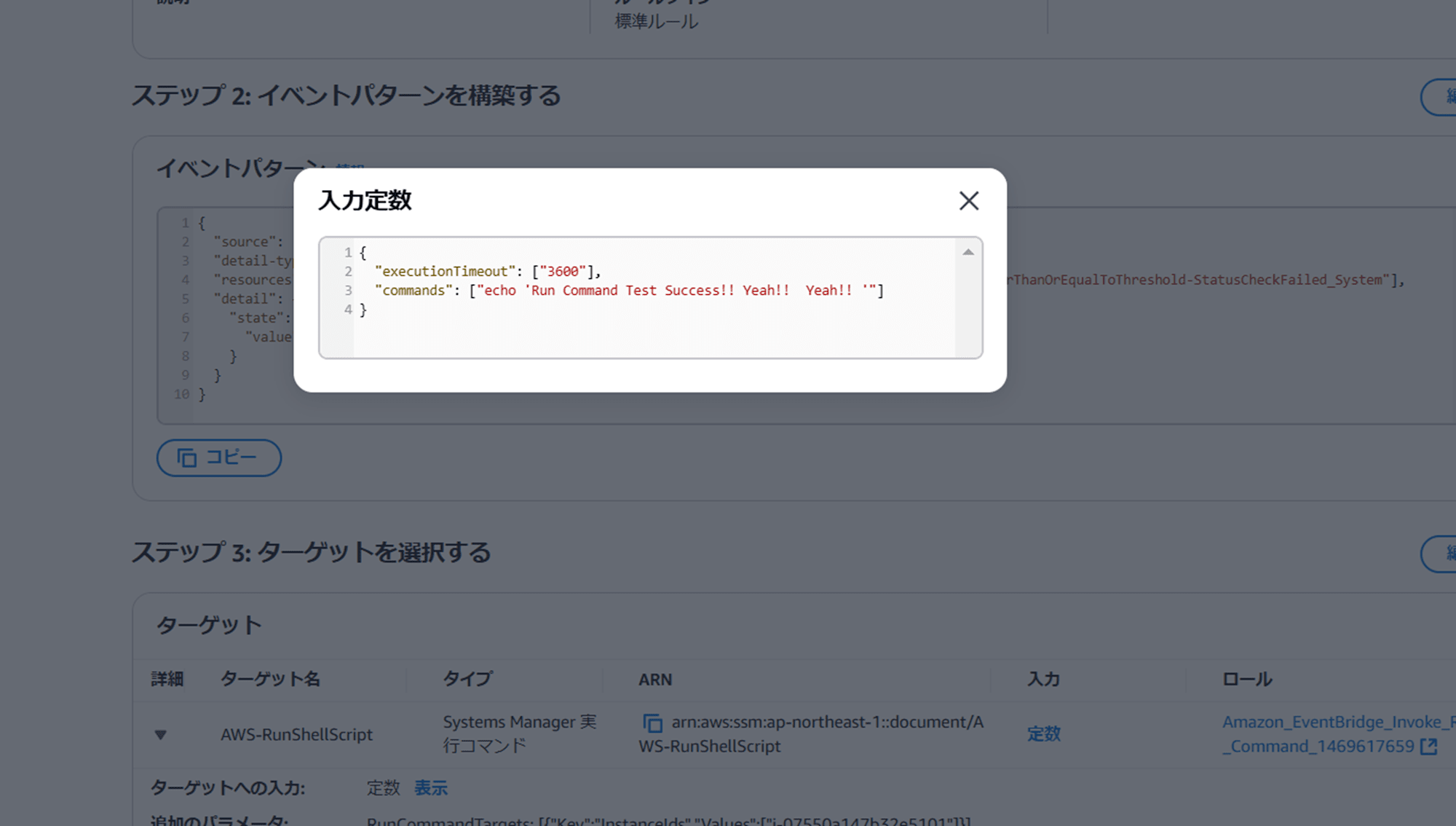
できました。
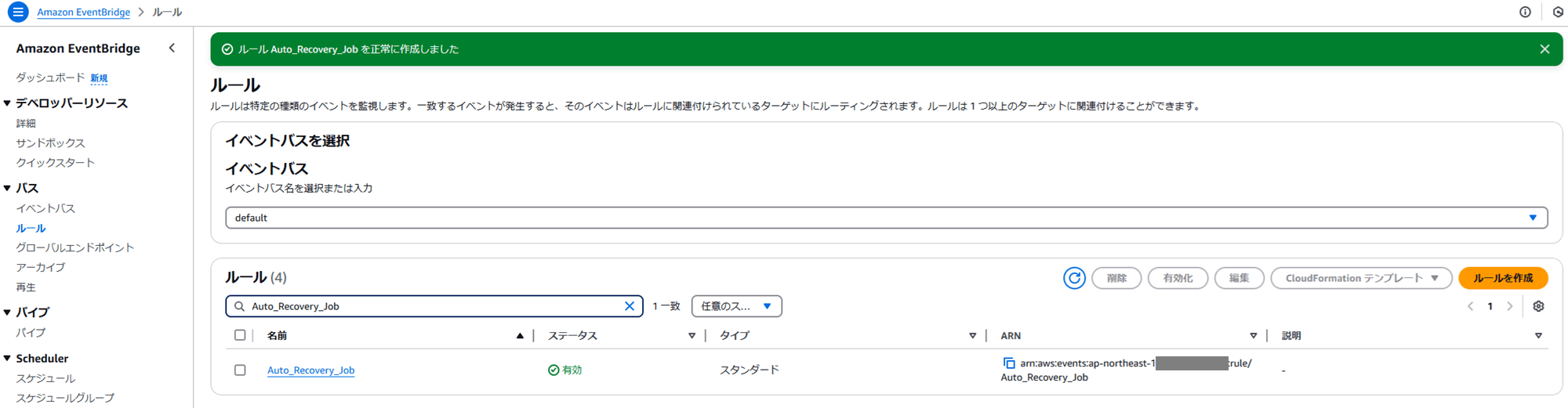
自動作成された EventBridge 用の IAM ロールに付与された権限はこうなっています。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "ssm:SendCommand",
"Effect": "Allow",
"Resource": [
"arn:aws:ec2:ap-northeast-1:123456789012:instance/i-07550a147b32e5101",
"arn:aws:ssm:ap-northeast-1:*:document/AWS-RunShellScript"
]
}
]
}
5. CloudWatch アラームをアラーム状態にする
CloudWatch アラームをアラーム状態にして、想定通り SSM Run Command でコマンド実行されるか確認します。
AWS 基盤側の障害を起こすことはできないので、アラーム状態を変更する API を使います。詳細は以下のブログを参照ください。
AWS CLI からアラームの状態を変更します。
実行コマンド
aws cloudwatch set-alarm-state \
--alarm-name "awsec2-i-07550a147b32e5101-GreaterThanOrEqualToThreshold-StatusCheckFailed_System" \
--state-value ALARM \
--state-reason "test"
▼実行結果
[cloudshell-user@ip-10-132-83-196 ~]$ aws cloudwatch set-alarm-state \
> --alarm-name "awsec2-i-07550a147b32e5101-GreaterThanOrEqualToThreshold-StatusCheckFailed_System" \
> --state-value ALARM \
> --state-reason "test"
[cloudshell-user@ip-10-132-83-196 ~]$
上記コマンドを実行すると、一時的にアラーム状態になります。
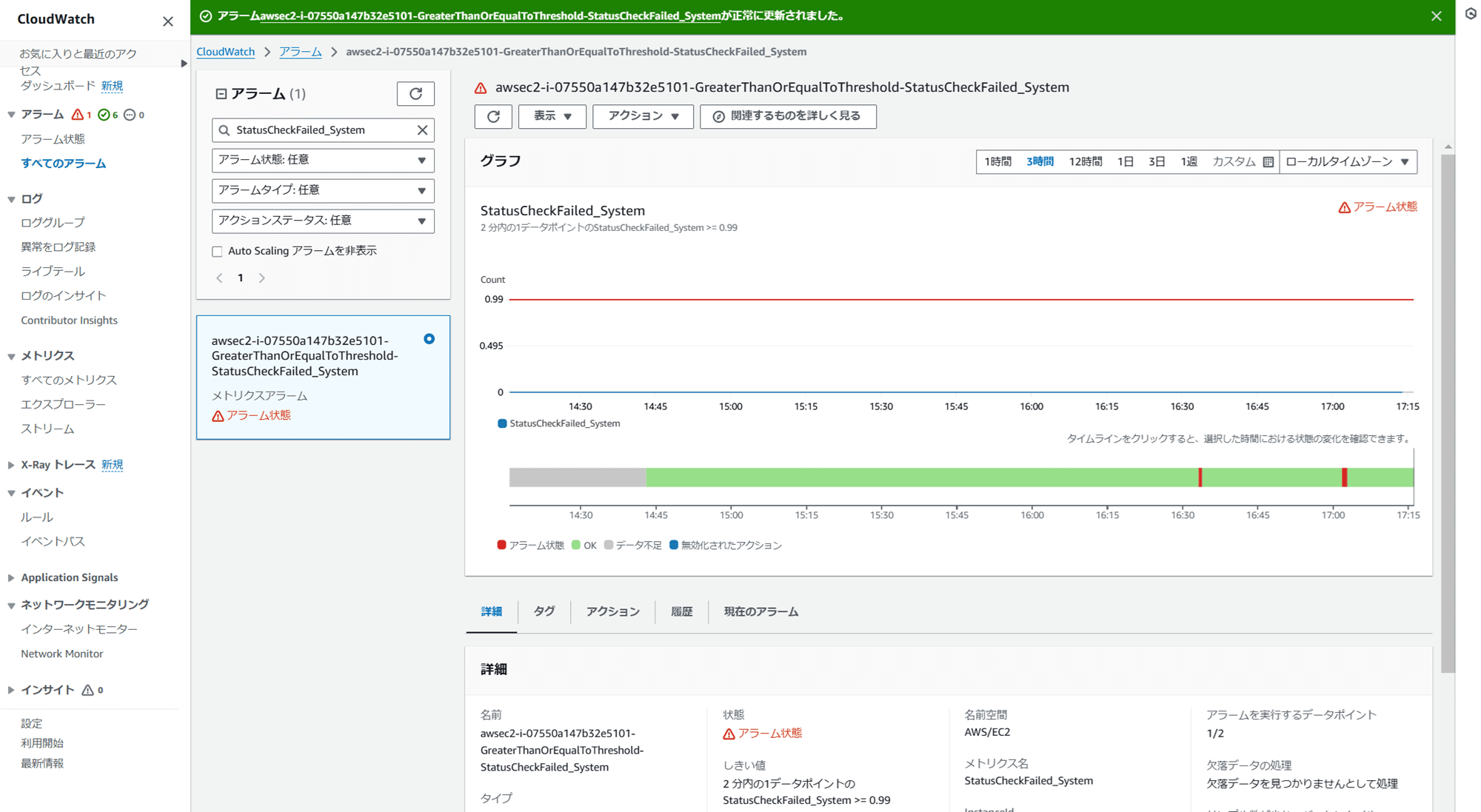
SSM Run Command を確認すると、コマンドの実行履歴が残っています。
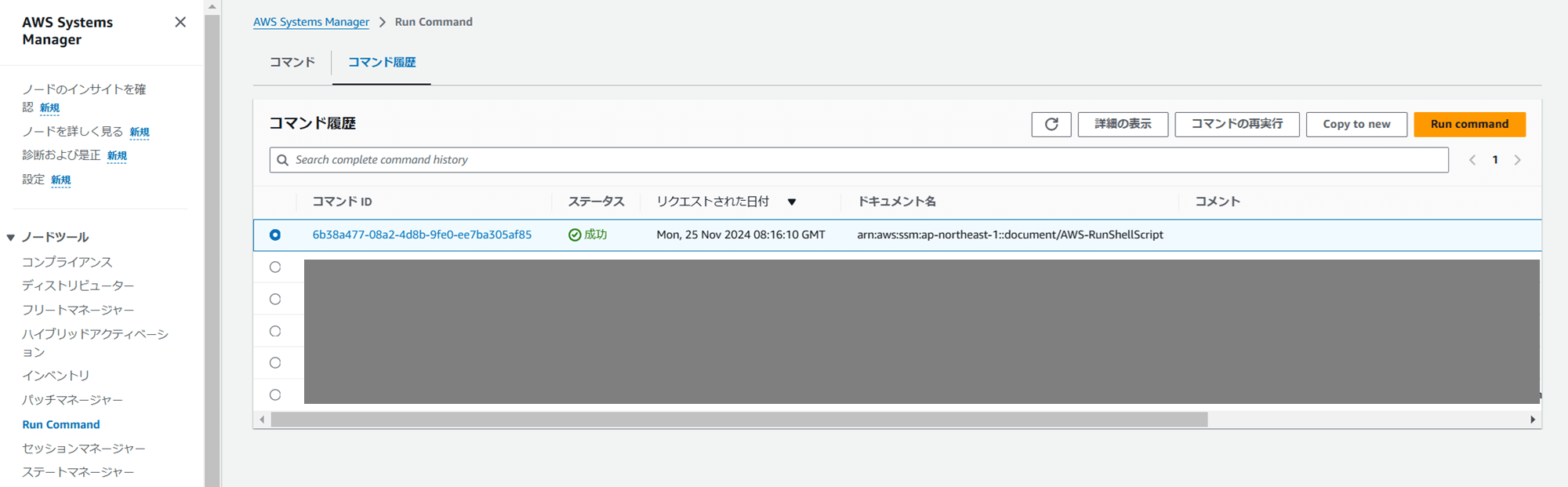
echo コマンドの結果が想定通り出力されています。
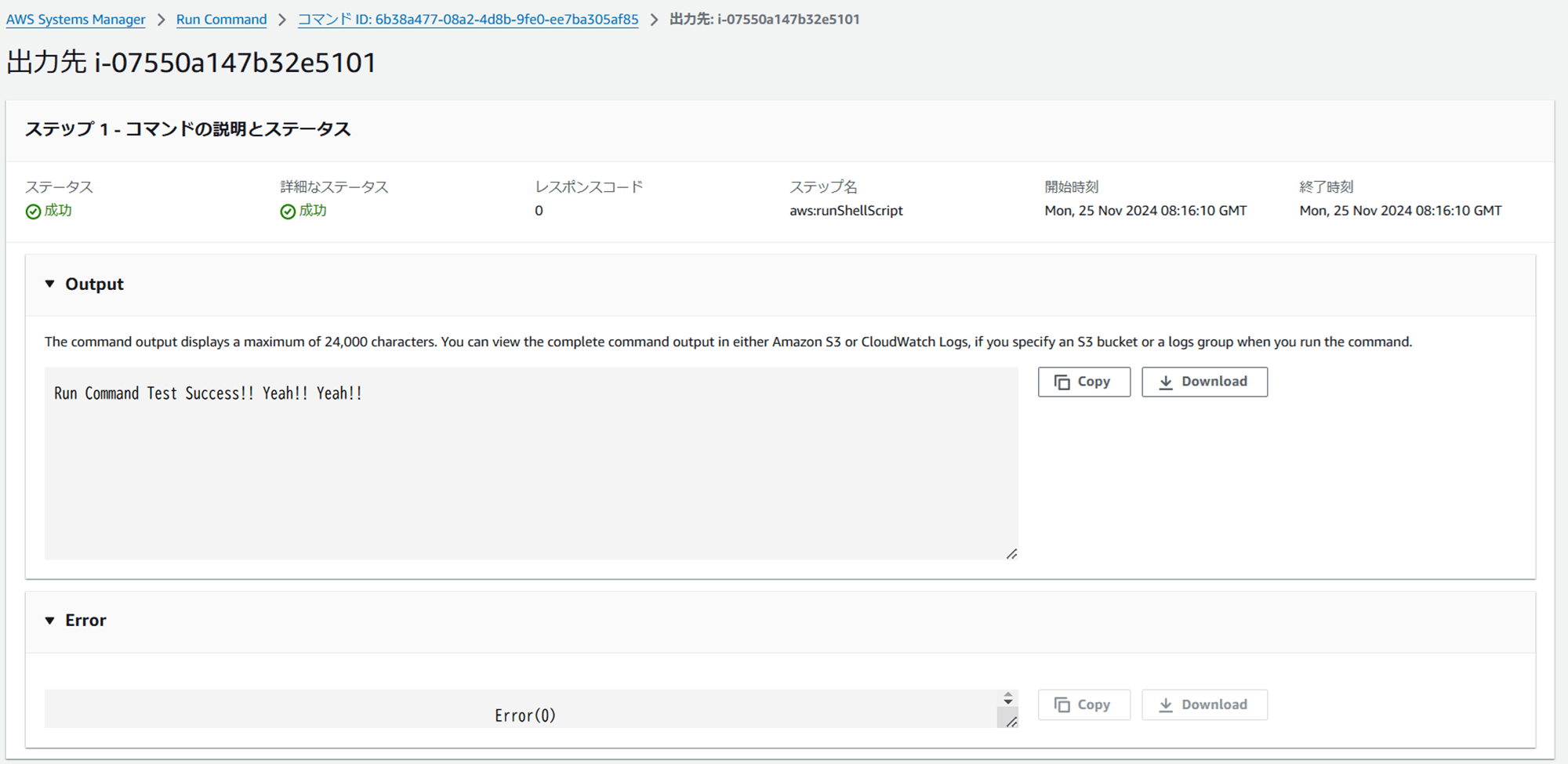
EventBridge ルールのモニタリング画面を見ると、MatchedEventsやInvocations` に Event がトリガーされた履歴が残っています。
何回か count が 2 の箇所があるのは、私がイベントパターンを間違って設定したせいでコマンドが二回実行されてしまった箇所です。
余談:[Auto Recovery] Amazon EC2 instance recovery: No action taken という件名のメールが届く
set-alarm-state コマンドを使ってテストアラート状態にすると、AWS から [Auto Recovery] Amazon EC2 instance recovery: No action taken という件名のメールを受信します。
これは、「対象 EC2 インスタンスにおいてEC2 自動復旧が起動したが、インスタンスの正常な状態を確認したので EC2 自動復旧は実行されなかった」。という内容の通知です。
ユーザー(私)が自分で意図的にアラーム状態を変更したので、想定通りの挙動です。インスタンスは正常起動しているので、何もする必要はありません。
終わりに
「0. 留意事項」で書きましたが、本ブログでの検証構成では SSM 連携が先に行われていないとコマンド実行できません。
これ以外の方法で Auto Recovery(インスタンスの自動復旧)発動時に特定のコマンドを実行させるには、SSM Run Command を使わずに Lambda などで適切な wait を挟んでキックするなどの方法もできそうです。しかし、それでは Lambda コードのメンテナンスが必要になってしまいます。
Auto Recovery(インスタンスの自動復旧)が発動するのは AWS 基盤側の障害という極めて稀なタイミングであることから、この稀な事象のために日々コードのメンテナンスをするのは億劫です。
個人的には以下が落としどころかなと思っています。
- Step Functions で順番を制御する
- SNS で通知してその時だけ手動でコマンドを実行する運用とする
後ほど Step Functions で制御する方法も検証してみます。
参考
- SSM エージェントをインストールした覚えがないのに、Systems manager の機能が利用できた理由を教えてください | DevelopersIO
- 既存 VPC 内の EC2 インスタンスに Systems Manager セッションマネージャーで接続するためのエンドポイントだけを一発で作成するCloudFormationテンプレートを作った | DevelopersIO
- SSM セッションマネージャーに必要なVPCエンドポイントが2つになっていた | DevelopersIO
- SSM Agent ステータスの確認とエージェントの起動 - AWS Systems Manager
- SSM Agent バージョン番号の確認 - AWS Systems Manager









